Sequence Models | Attention Model | Word Embeddings | More about Data Science
1. What is attention?
- Attention is a vector, often the outputs of dense layer using softmax function.
2. What is an attention model?
-
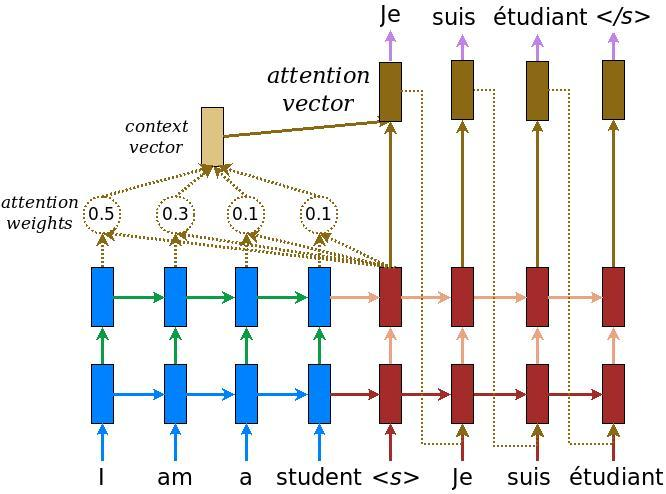
The attention model plugs a context vector into the gap between encoder and decoder.
-
According to the schematic below, blue represents encoder and red represents decoder
-
The context vector takes all cells’ outputs as input to compute the probability distribution of source language words for each single word decoder wants to generate.
3. Why do we use attention model?
-
Attention model allows machine translator to look over all the information the original sentence holds, then generate the proper word according to current word it works on and the context.
-
It can even allow translator to zoom in or out (focus on local or global features).
-
By utilizing attention model, it is possible for decoder to capture somewhat global information rather than solely to infer based on one hidden state.
4. How to solve a Human-Machine Translation problem using a attention-based bidirectional LSTM?
-
Try the Human-Machine Translation exercise on Coursera
(Translating human readable dates into machine readable dates)
Coursera notebook -
Take a look at my notebook
(Images need to be added)